Updraft Ensemble¶
Maps a single parcel solve over an ensemble of updraft speeds sampled from a
Gaussian distribution using jax.vmap. All ensemble members run in a single
JIT-compiled batched kernel — no Python loop.
Script: examples/updraft_ensemble.py
python examples/updraft_ensemble.py
python examples/updraft_ensemble.py --mean 1.0 --std 0.4 --n 1024 \
--out output/ensemble.nc --plot output/ensemble.png
Setup¶
import jax
import jax.numpy as jnp
import pyrcel as pm
from pyrcel.integrator import max_supersaturation, equilibrate_initial_state
# Build shared initial state
y0 = equilibrate_initial_state(T0, S0, P0, r_drys, kappas, Nis)
ts = jnp.linspace(0.0, t_end, n_out)
# Sample updraft speeds
V_samples = pm.sample_gaussian_updrafts(mean=0.5, std=0.25, n=256, seed=42)
# Batch over updraft speeds with vmap
def single_run(V):
args = (r_drys, Nis, kappas, accom, pm.ConstantV(V))
return max_supersaturation(y0, args, ts)
smax_batch = jax.vmap(single_run)(V_samples)
Console output¶
pyrcel v2 — updraft ensemble (N=256, mean=0.5 m/s, std=0.25 m/s)
─────────────────────────────────────────────────────────────────
S_max mean=0.352 % std=0.089 % min=0.127 % max=0.634 %
N_act mean=5.12e+08 m⁻³ std=1.34e+08 m⁻³
act_frac mean=0.512 std=0.134
─────────────────────────────────────────────────────────────────
Wrote output/ensemble.nc
Output distributions¶
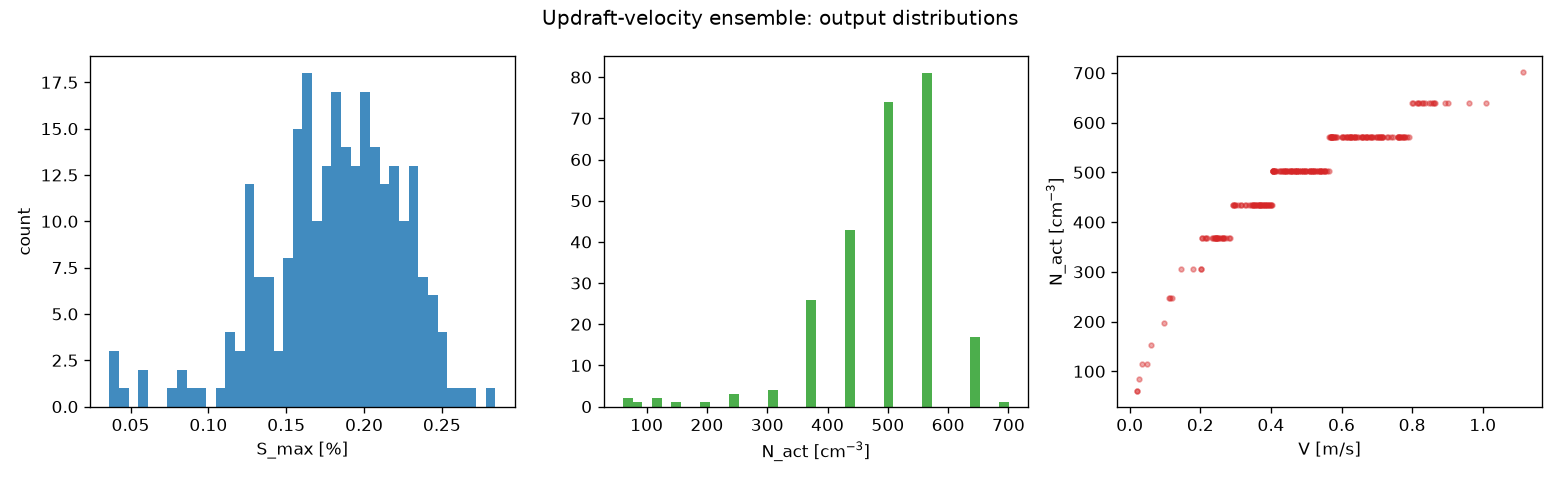
The figure shows the distributions of \(S_\text{max}\) (left) and \(N_\text{act}\) (right) across the 256-member ensemble. The spread reflects the sensitivity of activation to updraft speed: stronger updrafts cool faster, reach higher supersaturation, and activate more droplets.
Convenience wrapper¶
run_updraft_ensemble handles the full pipeline including aerosol setup, equilibration,
and ensemble execution:
result = pm.run_updraft_ensemble(
[aerosol], T0=283.15, S0=-0.02, P0=85000.0,
mean=0.5, std=0.25, n=256,
)
# result keys: "S_max", "N_act", "T_smax", "activated", "V"
print(result["S_max"].mean())
Performance notes¶
- The first
vmapcall triggers JIT compilation (~10–30 s for 100 bins). Subsequent calls with the same shapes are fast (< 1 s for n=256 on CPU). - On GPU,
vmapruns all members in parallel — typically 50–100× faster than a sequential CPU loop for large ensembles. t_endmust be long enough for the slowest member to reach its supersaturation maximum. The script auto-computest_end = z_cap / min(V).